When we are dealing with log files, we often need to count the number of times some keywords appear.
For example, count the number of times the access log ip appears. Here we can use linux awk command to handle.
➜ awk -F' ' '{a[$1]++}END{for(i in a) { print a[i], i}}' www.linuxcommands.site_nginx.log | sort -nrk1 | head -10
# cat www.linuxcommands.site_nginx.log| awk -F" " '{print $1}' | sort| uniq -c | sort -nrk1 | head -10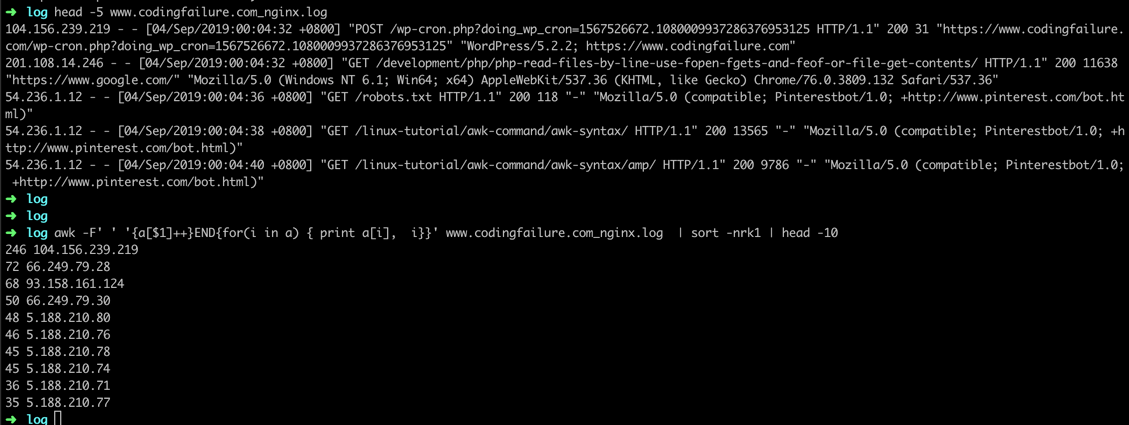
Like the result above, it is similar to the sql group by command.
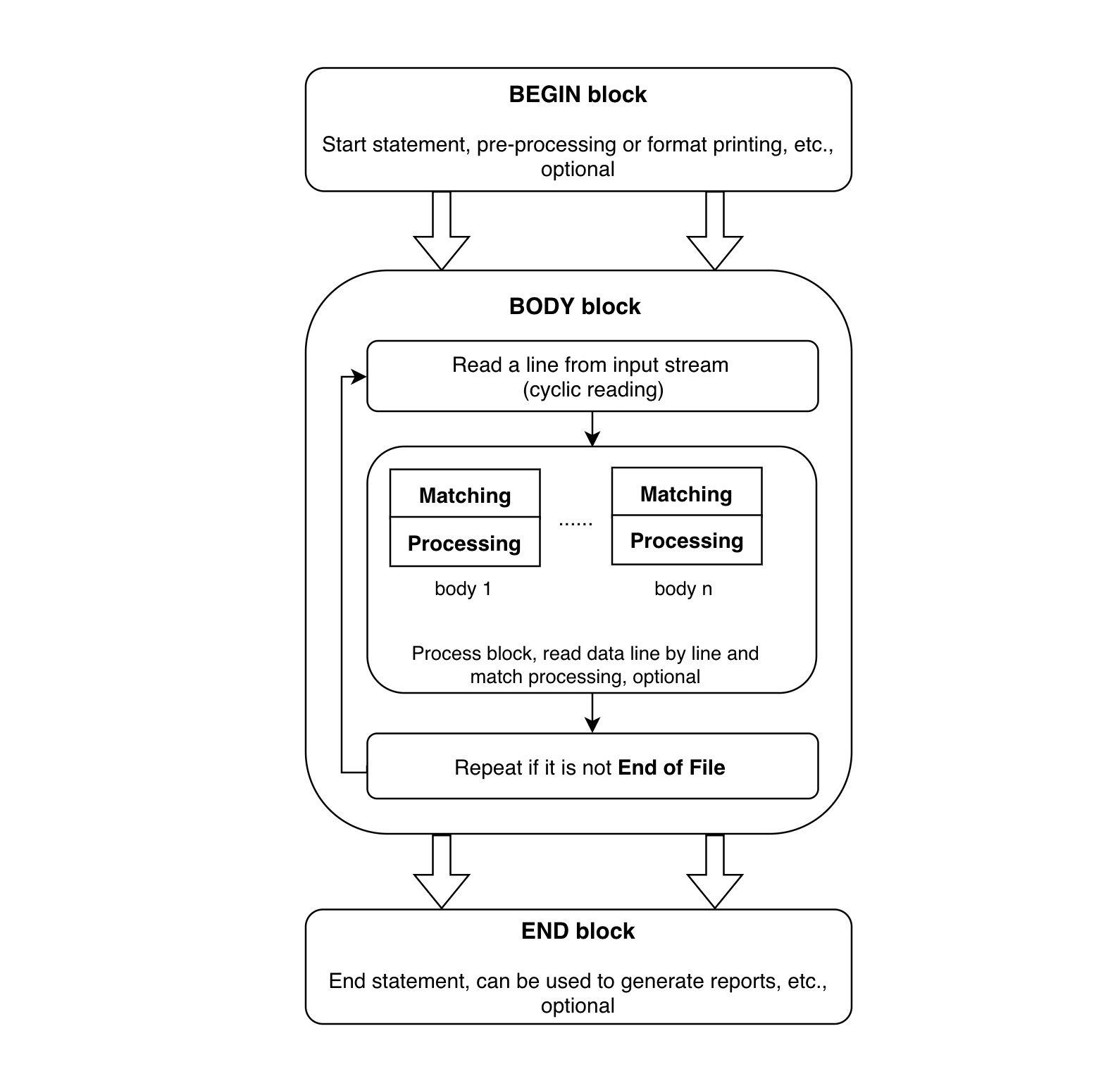
The above detailed explanation is as follows:
1. awk -F’ ‘
Split by space.
2. {a[$1]++}
Use array to count the number of occurrences of the first field.
3. END{for(i in a) { print a[i], i}}
End statement, loop print the value and key of the array a. That is, the number of occurrences of field 1 and the content of field 1 .
4. | sort -nrk1
Put the contents of step 3 into the pipeline and sort by natural value according to the first field.
5. | head -10
Put the contents of step 4 into the pipeline and print the top 10 most.
OK.