
sed is a stream editor.
A stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
Sed is mainly used to automatically edit one or more files, simplify the repeated operation of files, write conversion programs, etc.
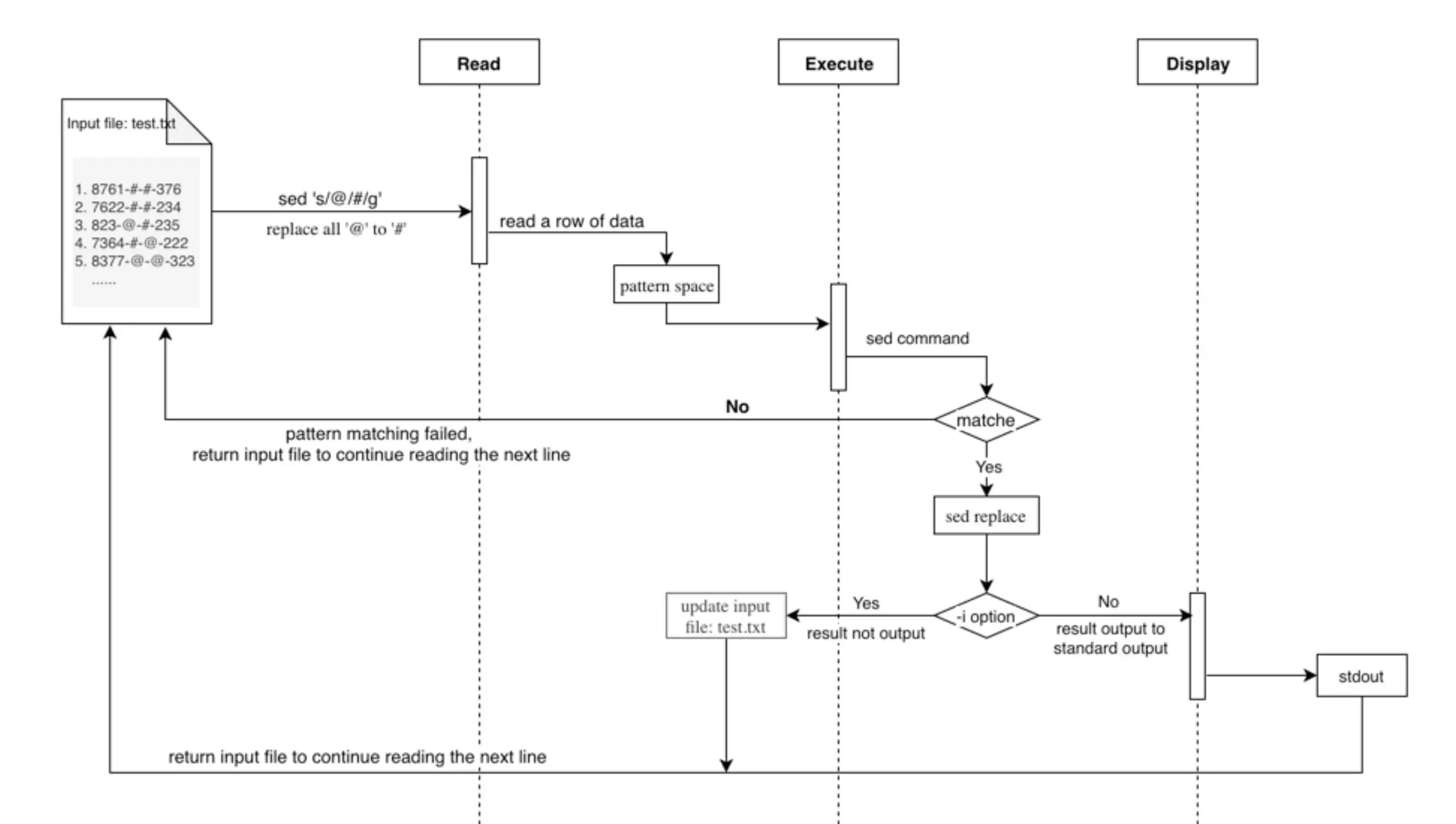
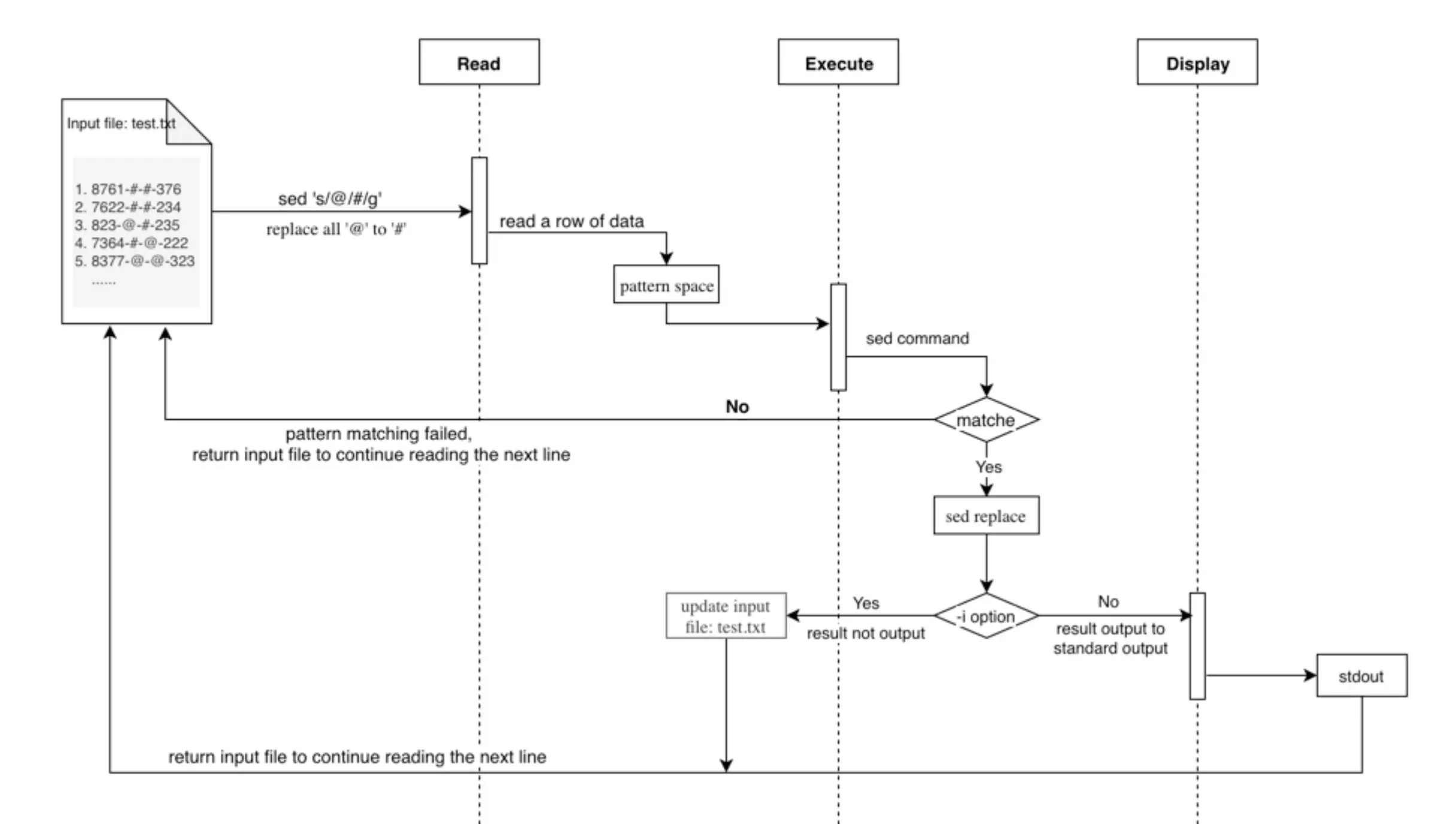
sed workflow
The sed workflow can be easily understood as:
Read –> Execute –> Display -> … -> Read –> Execute –> Display
- Read: Read a line from input stream
- Execute: Execute sed command(s) on a line
- Display: Display result on output stream
Debug

how sed works
sed maintains two data buffers: the active pattern space, and the auxiliary hold space. Both are initially empty.
sed operates by performing the following cycle on each line of input:
First, sed reads one line from the input stream, removes any trailing newline, and places it in the pattern space.
Then commands are executed; each command can have an address associated to it: addresses are a kind of condition code, and a command is only executed if the condition is verified before the command is to be executed.
When the end of the script is reached, unless the -n option is in use, the contents of pattern space are printed out to the output stream, adding back the trailing newline if it was removed. Then the next cycle starts for the next input line.
Unless special commands (like ‘D’) are used, the pattern space is deleted between two cycles. The hold space, on the other hand, keeps its data between cycles.
(from:https://www.gnu.org/)
hold space and pattern space explain
With the help of stackoverflow.com example and sedsed debugging tool.
When sed reads a file line by line, the line that has been currently read is inserted into the pattern buffer (pattern space). Pattern buffer is like the temporary buffer, the scratchpad where the current information is stored. When you tell sed to print, it prints the pattern buffer.
Hold buffer / hold space is like a long-term storage, such that you can catch something, store it and reuse it later when sed is processing another line. You do not directly process the hold space, instead, you need to copy it or append to the pattern space if you want to do something with it. For example, the print command p prints the pattern space only. Likewise, s operates on the pattern space.
Here is an example:
sed -n '1!G;h;$p'(the -n option suppresses automatic printing of lines) There are three commands here: 1!G, h and $p. 1!G has an address, 1 (first line), but the ! means that the command will be executed everywhere but on the first line. $p on the other hand will only be executed on the last line. So what happens is this:
1. first line is read and inserted automatically into the pattern space
2. on the first line, first command is not executed; h copies the first line into the hold space.
3. now the second line replaces whatever was in the pattern space
4. on the second line, first we execute G, appending the contents of the hold buffer to the pattern buffer, separating it by a newline. The pattern space now contains the second line, a newline, and the first line.
5. Then, h command inserts the concatenated contents of the pattern buffer into the hold space, which now holds the reversed lines two and one.
6. We proceed to line number three — go to the point (3) above.
Finally, after the last line has been read and the hold space (containing all the previous lines in a reverse order) have been appended to the pattern space, pattern space is printed with p. As you have guessed, the above does exactly what the tac command does — prints the file in reverse.
sedsed debug

PATT: Contents of the PATTERN SPACE buffer HOLD: Contents of the HOLD SPACE buffer COMM: The sed command being executed $ Terminates the PATT and HOLD contents
sed syntax
sed [-Ealn] [-e command] [-f command_file] [-i extension] [file ...]Common options:
- -e command
Append the editing commands specified by the command argument to the list of commands.
- -i extension
Edit files in-place, saving backups with the specified extension. If a zero-length extension is given, no backup will be saved. It is not recommended to give a zero-length extension when in-place editing files, as you risk corruption or partial content in situations where disk space is exhausted, etc.
- -n
By default, each line of input is echoed to the standard output after all of the commands have been applied to it. The -n option suppresses this behavior.
Action options:
- a: appending text after a line.
- i: insert text before a line.
- c: replaces the line(s) with text.
- d: delete the pattern space.
- p: print out the pattern space.
- s: The s command (as in substitute) is probably the most important in sed and has a lot of different options. the s command attempts to match the pattern space against the supplied regular expression regexp; if the match is successful, then that portion of the pattern space which was matched is replaced with replacement.
Exit status
An exit status of zero indicates success, and a nonzero value indicates failure. GNU sed returns the following exit status error values:
- 0
Successful completion. - 1
Invalid command, invalid syntax, invalid regular expression or a GNU sed extension command used with –posix. - 2
One or more of the input file specified on the command line could not be opened (e.g. if a file is not found, or read permission is denied). Processing continued with other files. - 4
An I/O error, or a serious processing error during runtime, GNU sed aborted immediately.
sed examples and use cases
sed add to end of line
8761-#-#-376
7622-#-#-234
…
update:
8761-#-#-376-@
7622-#-#-234-@
…
➜ sed 's/$/-@/' test.txt
The syntax of the s command is ‘s/regexp/replacement/flags’.
The s command can be followed by zero or more of the following flags:(I use it often)
g Apply the replacement to all matches to the regexp, not just the first.
number Only replace the numberth match of the regexp.
For more information, please see: The s Command
sed add line after match (sed add newline)
➜ sed '/235/a12312312' test.txt
sed delete match line
➜ sed '/235/d' test.txt
sed replace regex
➜ sed 's/[#@]//g' test.txt
There are many examples in the sed manual.
sedsed
sedsed can debug, indent, tokenize and HTMLize your sed scripts.
In debug mode it reads your script and add extra commands to it. When executed you can see the data flow between the commands, revealing all the magic sed does on its internal buffers.
In indent mode your script is reformatted with standard spacing.
In tokenize mode you can see the elements of every command you use.
In HTMLize mode your script is converted to a beautiful colored HTML file, with all the commands and parameters identified for your viewing pleasure.
With sedsed you can master ANY sed script. No more secrets, no more hidden buffers.
Detailed usage:https://aurelio.net/projects/sedsed/
SEE ALSO
- https://www.gnu.org/software/sed/manual/sed.html#The-_0022s_0022-Command
- https://aurelio.net/projects/sedsed/
- https://stackoverflow.com/questions/12833714/the-concept-of-hold-space-and-pattern-space-in-sed
Best Article
Linux common commands tutorial and use examples
Awk tutorial: awk syntax and awk examples