Awk is a very powerful text processing command, usually using it to process data and generate reports.
Awk like other languages, supports built-in variables, built-in functions, conditional judgments, loop statements, etc.
Let’s learn how to use the awk command in the Linux.
Awk syntax
Basic format
awk [options] 'pattern{ commands }' fileFull format
awk [-F|-f|-v] 'BEGIN{ commands } pattern{ commands } END{ commands }' fileAwk options
- -F :
Specifies a delimiter - -f :
Call script - -v :
Defining variables var=value
Awk built-in variable
- $0 :
Represents the entire current line - $1 :
First field per line - NF :
Field quantity variable - NR :
Record number per line, multi-file record increment - FNR :
Similar to NR, but multi-file records do not increase, and each file starts from 1 - FS :
Define delimiters - RS :
Enter the record separator, default is a newline - ~ :
Match, not exact comparison with == - !~ :
Mismatch, inaccurate comparison - == :
Equal, must be all equal, accurate comparison - != :
Not equal, exact comparison - && :
And operator - || :
Or operator - OFS :
Output field separator, default is also a space, can be changed to tabs, etc. - ORS :
Output record separator, which defaults to a newline character, that is, the processing result is also output to the screen line by line.
Awk workflow
The awk statement has three parts: BEGIN statement block, general statement block that can use pattern matching, and END statement block.
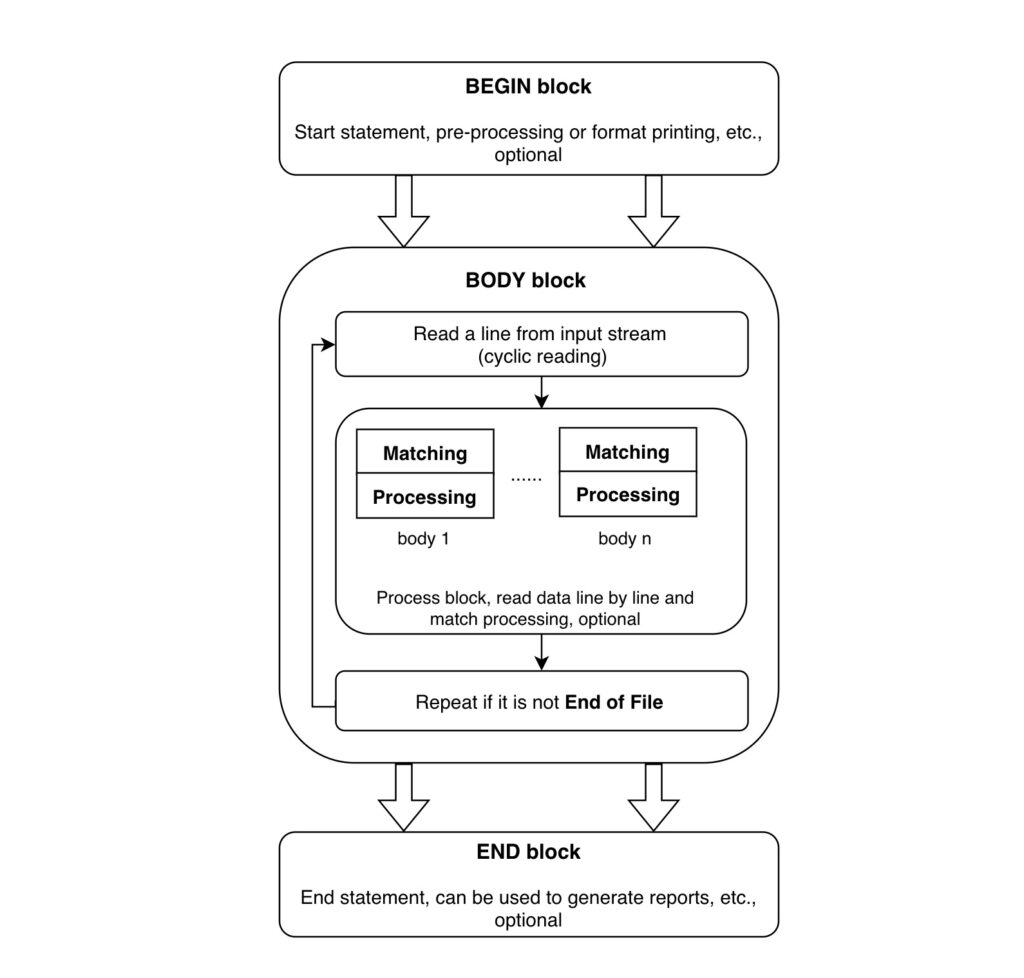
- Step 1
First, execute the statements in the BEGIN {commands} statement block. - Step 2
Then, read a line from the file or standard input (stdin), execute the pattern {commands} block, which scans the file line by line, and repeats the process from the first line to the last line until all files are read. - Step 3
Finally, when the end of the input stream is read, the END {commands} block is executed.
Awk examples
1. Use awk begin and end to format output
In the following example, we will demonstrate the BEGIN and END pattern.
➜ awk '
BEGIN{print "=======begin======="}
{print $0;}
END{print "========end========"}
' test.txt

2. Split a string by specifying a delimiter
Separating fields according to delimiters is a very powerful feature of awk. It supports single or multiple delimiters to separate fields.
In the following example, we will use the -f option or the FS variable for delimiter separating strings.
2.1 awk -F option example
- awk delimiter tab
Use tab as a delimiter to separate fields.
➜ ~ echo "hello world awk tab" | awk -F"\t" '{print $1,$3}'
hello awk
➜ ~- awk delimiter space
Use space as a delimiter to separate fields.
➜ ~ echo "hello world awk tab" | awk -F" " '{print $1,$3}'
hello awk- awk multiple delimiters
Use “:” and “#” as delimiters to separate fields.
$ cat test_1.txt | awk -F[:=] '{print $1, $2, $3, $4, $5}'
2.2 awk FS variable example
The FS variable and -F option are equivalent.
➜ cat test_1.txt | awk 'BEGIN{FS="[:=]";}{print $1, $2, $3, $4, $5}'
- Use awk split example
$ cat test_1.txt | awk '{split($0, a, "[:=]");print a[1], a[2], a[3], a[4], a[5]}'
3. Awk custom function tutorial
The syntax of the custom function is:
function function_name(argument1, argument2, ...)
{
function body
}- Function_name
The name of a custom function.
Function names should start with letters, followed by free combinations of numbers, letters, or underscores.
Keywords retained by awk cannot be used as the name of user-defined functions. - Function parameters
Custom functions can accept multiple input parameters separated by commas. Parameters are not required.
We can also define functions that do not have any input parameters. - Function body
The body part of a function, which contains program code.
In the following example, we will use the awk custom function to calculate the area value.
➜ vim functions.awk
# calculated area
function area(a, b)
{
return a * b
}
# main function
function main(a, b)
{
result = area(a, b)
print "area = ", result
}
# start statement
BEGIN {
main(2, 4)
}
➜ awk -f functions.awk
area = 8

4. Awk built-in functions examples
4.1 Print function examples
In the following example, we will show you the awk print function, which prints file lines or file specified columns.
awk print $0: print the entire line
$ echo "test" | awk '{print}'
$ echo "test" | awk '{print $0}'

- awk print column
awk can use the -F option or FS variable to process the text and format the output. In the following awk examples, we print any column or any row.
awk print first column
➜ ~ echo "a:B:C:CS:DDDD" | awk -F":" '{print $1}'
a
➜ ~ echo "a:B:C:CS:DDDD" | awk -F":" '{print $2}'
Bawk print multiple columns
➜ ~ echo "a:B:C:CS:DDDD" | awk -F":" '{print $2,$5}'
B DDDDprint specific columns
$ awk '{print $2}' test.txt

awk print last column/field
Using the awk NF variable, print the last column (the last field).
➜ awk '{print $NF}' test.txt 
use NR to print specific rows
Using the awk NR variable, print the second line.
$ awk 'NR==2{print}' test.txt
2 3 4awk print line number
Using the awk NR variable, print the line number of each line.
$ awk '{print NR, $0}' test.txt

Use OFS to specify the delimiter formatted output
$ ➜ ~ echo "a:B:C:CS:DDDD" | awk -F":" '{print $2,$5}' OFS="|"
B|DDDD
4.2 Substr func examples
Awk substr returns a substring of the specified length from the start position; if the length is not specified, it returns a substring from the start position to the end of the string.
syntax
#Returns a string of length starting at position
substr(string, position, length)
#Returns a string from position to the end
substr(string, position) examples
➜ ~ echo "ABCDEFG" | awk '{print substr($0, 3)}'
CDEFG
➜ ~ echo "ABCDEFG" | awk '{print substr($0, 3, 2)}'
CD4.3 Split func examples
Awk split function allows a string to be separated into words and stored in an array.
split(SOURCE,DESTINATION,DELIMITER)
split(SOURCE, DESTINATION) -- If the third parameter is not provided, awk defaults to the current FS value.
- SOURCE : Text to be analyzed
- DESTINATION : Store analytical results
- DELIMITER : Text separator- Use Default Delimiter – Space
➜ cat test.txt
1 2 3
2 3 4
3 4 5
➜ cat test.txt | awk '{split($0, a, " ");print a[1], a[2], a[3]}'
1 2 3
2 3 4
3 4 5➜ cat test.txt
1 2 3
2 3 4
3 4 5
➜ cat test.txt | awk -F" " '{split($0, a);print a[1], a[2], a[3]}'
1 2 3
2 3 4
3 4 54.4 Length func examples
Awk length function returns the number of characters in the entire record.
length(string)example
➜ echo "ABCDEFG" | awk '{print length($0)}'
74.5 System func examples
Awk system function executes system commands.
system(Linux command)- To generate multiple files in batches
➜ awk 'BEGIN {do {++i; system("touch file_num_" i "_test") } while (i<9) }'

- batch rename
➜ ls | grep test | awk '{system("mv "$0" "substr($0,0,10)"")}'
5. Awk conditional judgment statement
5.1 If else statement
Regardless of the development language, the if else conditional statement is one of the most used features.
In the following examples, we will introduce the use of awk if, else if conditional statements and the use of multiple conditional judgments
if() {
...
} else if {
...
} else {
...
}➜ cat test-2.txt
123#192.168.1.33#google#20190622#/url/test
➜ awk -F"#" '{
if($1==12)
print $1;
else if($3 == "google")
print $3;
else
print $0
}' test-2.txt

5.2 Ternary judgment
Ternary operations are common in development. Awk also supports ternary judgment, and in the following example, we will demonstrate how to use awk ternary operations for conditional judgment.
➜ ~ echo "100:23" | awk -F ":" 'BEGIN{res=$1>32?"true":"false";}{print res}'
false
6. Examples of using loop statements
6.1 For loop
In the following example tutorial, we will introduce the use of awk for loop function in daily log processing.
➜ cat test-2.txt
192.168.1.1#10.10.83.92#/url/test#google#1234322344
➜ awk -F"#" '{
for(i=1;i<=NF;i++) {
if($i == "google") {
print "NF=" i ", this is a refer";
} else {
print "NF=" i "," $i
}
}
}' test-2.txt
The awk command is very widely used in linux/unix, and I will share it with you in subsequent articles.
Reference
https://www.gnu.org/software/gawk/
https://en.wikipedia.org/wiki/AWK
Can you make one for SED?
Ok, I am going to.
https://www.linuxcommands.site/linux-text-processing-commands/linux-sed-command/gnu-sed-syntax-and-sed-examples/